
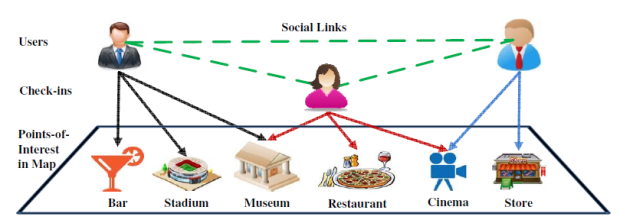
Point of Interests(POI) can be defined as an attractive location or an item which someone may find useful of some particular interest. A brief description related to check-in based POI can be found in Joint Modeling of User Check-in Behaviors for Real-time Point-of-Interest Recommendation.
THE IDEA
People generally express their opinion regarding their purchase in form of reviews on e-commerce websites or in form of web blog posts. A simple solution to learn people’s interests is to extract information from these reviews regarding user’s interest and whenever the user is in a new geographic location he/she can be notified about the nearby interesting places based on his/her review history. A common approach to this problem is to process the reviews for opinion mining/sentiment analysis. Opinion mining can be inefficient for extraction of the point of interests for an user. With sentiment analysis we can only identify a review as positive or negative whereas possible interest of the user remain unidentified. A better approach is to use some algorithms for topic modeling such as Latent Dirichlet Allocation(LDA) and newly introduced word vector models(Word2vec and GloVe) for the problem of POI generation.
Latent Dirichlet Allocation(LDA)
LDA is a topic modelling technique that determines how the documents in a database are created. This generative model also describes how words in a documents are generated. In simple words LDA works like K-Means clustering, here the points in a clusters are the words. Each cluster constitutes a topic and the K clusters are essentially the K unique topics or the POIs.
For LDA, I will use the Gensim package in Python. Prepare the dataset as follows:
data = ["When I moved to Charlotte, Eastland Mall was not a bad place.  Perhaps not great, but really not all that bad."
"I had heard really good things about Bubba's",
"While I like the Melting Pot, I just can't help but be amazed at the place."
"The ambiance of The Capital Grille is excellent."]
I have taken these reviews from Yelp dataset which consists of reviews related to food. As you can see each review contains a lot of unnecessary words like I, had, is, etc. These extraneous words contains no information regarding POI. For this purpose we extract all the nouns from the reviews and train the models with the datasets having this modification. The next step is to construct a document term matrix which will be used to create a bag of word model. This can be done with following lines
from gensim import corpora, models dictionary = corpora.Dictionary(data) corpus = [dictionary.doc2bow(lines) for lines in data]
Finally, to use the LDA module use the following command
ldamodel = gensim.models.ldamodel.LdaModel(corpus,num_topics=3,id2word = dictionary,passes=20)
Where, num_topics are the number of POIs and passes is the number of times we want to iterate through the dataset for training the LDA model. The results by the LDA can be seen as
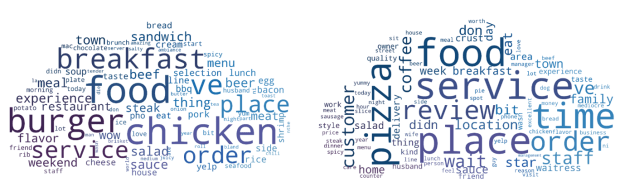
print(ldamodel.print_topics(num_topics=2, num_words=6)) 0.032*chicken + 0.031*place + 0.027*love + 0.018*taco + 0.017*meat + 0.015*salad 0.043*pizza + 0.039*place + 0.032*burger + 0.029*location + 0.024*order + 0.021*time
With the help of LDA we can obtain the clusters but being a unsupervised technique the label corresponding to each cluster (the POI) is to be given manually. Thus, for the above results we can assign the first POI as non-veg and the second POI as fast food. Similarly, we can generate as many POI as we like as long as LDA is able to generate well defined clusters.
The results can also be illustrated with the help of word clouds. The word clouds gives weightage to the terms that form a particular topic. Larger weight of a term is shown by large word size.
PROBLEM WITH LDA
With the help of LDA we can generate POIs as topics but these topics or clusters are not disparate from each other. By this I mean that some words are present in both of the clusters, thereby causing ambiguity. Words like place, service, salad, etc. are present in both of the topics with noticeable weight. For now the number of topics are taken to be 2 and we can see the problem even with such a smaller value.
Lets try word vector technique for POI generation.
WORD VECTOR
Word2vec models represents distribution of word vectors in low dimensional space, as given in Efficient Estimation of Word Representations in Vector Space. Word2vec is a recurrent neural network based model which tries to learn lower dimensional vector representation from the given vocabulary. In simple terms word vector models represents each word with a vector and we train a neural network on the dataset of sentences (here reviews) that can learn the contextual relationship among words. Words like pizza, burger and crust are contextually closer than bear, wine and brews. With the help of word vector model it is possible to update the vectors of all these six words in such a way pizza, burger and crust lie in one cluster and the rest lie in other. The first cluster can be given fast food as POI and the second cluster clearly lies in drinks category.
Prepare the dataset as
data = [['I', 'had', 'heard', 'really', 'good', 'things', 'about', "Bubba's"],
[['While', 'I', 'like', 'the', 'Melting', 'Pot,', 'I', 'just', 'cant', 'help', 'but', 'be', 'amazed', 'at', 'the', 'place.']]
['The', 'ambiance', 'of', 'The', 'Capital', 'Grille', 'is' ,'excellent']]
The Word2vec model is also present in the Gensim module. Use the following command for training a Word2vec model.
model = gensim.models.Word2Vec(data,min_count=1,size=200,workers=6)
The size parameter is the dimension of the word vector and workers are the number of multicores that you want to use. For multicore the machine should support hyperhreading and multicore support.
You can check the similarity between two words using the similarity parameter provided in the Gensim module. Internally similarity module computes the cosine similarity between two word vectors.
model.similarity('pizza','burger')
0.73723527
model.similarity('wine','beers')
0.75213573
model.similarity('pizza','wine')
0.03872634
As you can see the word vectors of pizza and burger, wine and beer, are closer as compared to pizza and wine. Thus the Word2vec is able to capture the underlying context among words.
Since each word is now represented by a vector therefore it is possible to visualize the word vectors with the help of scatter plots. For this we need to reduce the dimension of all the vectors with the help of PCA. I will set the number of dimension to 3 so that it is possible to plot the word vectors.
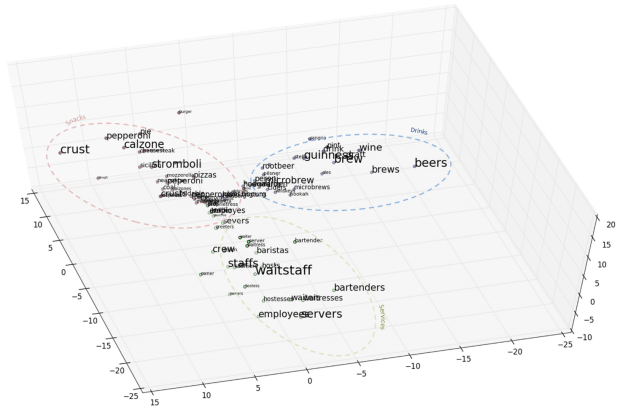
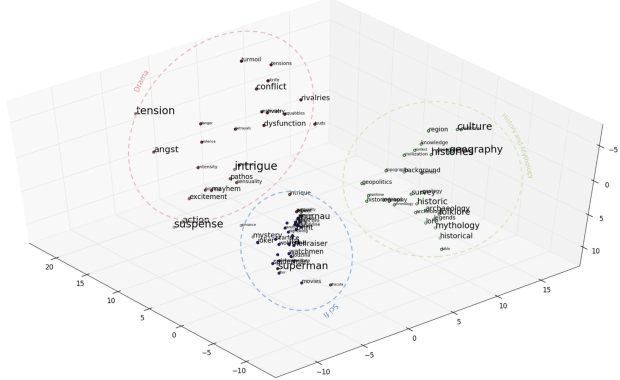
The 3D plot shows the clusters formation by the vectors generated by Word2vec. We can manually label these categories as Snacks, Drinks and Services. The three categories as shown in above figure represents the three POIs from the Yelp restaurant dataset. The results of the Amazon review dataset for movie category is given by figure below
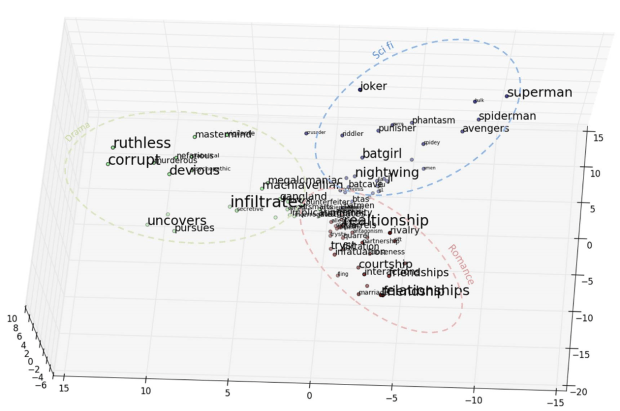
The categories that are manually labelled are Sci fi, Drama and Romance. Similarly, the results of the book dataset is given in the following figure where the categories are Drama, Sci fi and, History and Mythology.
CONCLUSION
In this posts we have seen the problem of Point of Interests generation based on user reviews. We compared the results of LDA with Word2vec and saw that the results of word vector models are better in quality.
WHAT’S NEXT?
Here, I have not shown the problem related to word vector models. While experimenting with these models I came across an issue related to the update of the vectors. I will include the details related to the problem in a future post.
