
In this post, I am going to discuss Deep CorrNet that is described in Correlational Neural Network which is a Common Representation Learning (CRL) technique. I have implemented CorrNet in Python using Keras, Theano as the backend, and Scikit Learn. I have used the same dataset as described in the paper achieving better results across all metrics for transfer learning as well as for data reconstruction. This post covers theoretical as well as step-wise implementation details.
Text Based Question Answering
Automatic question answering is a widely studied problem in natural language processing with applications including entity extraction and information retrieval. Most of the existing works in this area tackles a restricted problem of factoid question answering, while others use answer sentence selection. As of now not much work has been done on text-based question answering, where sufficiently long answers are generated corresponding to each question. Continue reading
Transliterated Queries 2 – Deep Learning
This article is a successor to the previous post Simple Markov Model for correcting Transliterated Queries. The key feature of the introduced model are:
- Can be retrained on a new dataset of well spelled queries in mixed languages such as Hindi-English, English-French, Hindi-Bengali, etc.
- No need of an annotated dataset, only need well spelled queries.
- Can be trained on smaller dataset – ~10K queries, giving reasonable performance.
- A trained model on English corpus is provided, queries are taken from Yahoo webscope – 150K questions. Continue reading
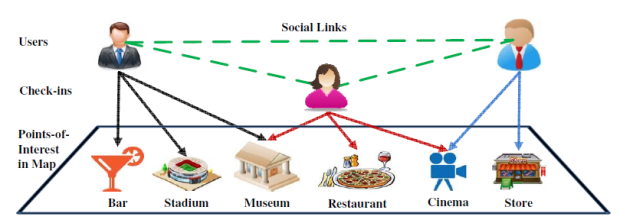
Point of Interest
Point of Interests(POI) can be defined as an attractive location or an item which someone may find useful of some particular interest. A brief description related to check-in based POI can be found in Joint Modeling of User Check-in Behaviors for Real-time Point-of-Interest Recommendation.
Deep Cloud
Deep learning models are known to be computationally expensive and can take several days to train depending upon the size of data-set. To reduce the processing time the use of GPU and distributed computing using MapReduce can be seen these days. In this post I will show how to combine both of these processing paradigm. Once the learning algorithm is implemented using MapReduce it is possible to use the model on the Elastic Map Reduce(EMR) platform provided by Amazon Web Services (AWS). The code is available on Github.
-
I will use Mrjob’s MapReduce implementation in Python to implement a simple neural network.
-
Each mapper or individual machine is equipped with a GPU and uses Theano/Tensorflow for GPU multi-threading. Continue reading
Simple Markov Model for correcting Transliterated Queries
The use of mixed languages allows people to express and communicate beyond the constraints of one language. Recently, a common term that has been given to these mixed languages is Hinglish. The use of mixed scripts can be seen in social media such as Watsapp & Facebook, e-commerce like Amazon & Flipkart, and web blogs like this one. Some of the corporate organizations use these scripts to create advertisement taglines such as khushiyon ki home delivery – Dominos, or yeh dil maange more…aha! – Pepsi.


Till now most of us know this usage as Hinglish, yet there is a specific term in linguistics for sentences formed in these mixed scripts, and that is Transliteration, as described in Query Expansion for Multi-script Information Retrieval.
