
This article is a successor to the previous post Simple Markov Model for correcting Transliterated Queries. The key feature of the introduced model are:
- Can be retrained on a new dataset of well spelled queries in mixed languages such as Hindi-English, English-French, Hindi-Bengali, etc.
- No need of an annotated dataset, only need well spelled queries.
- Can be trained on smaller dataset – ~10K queries, giving reasonable performance.
- A trained model on English corpus is provided, queries are taken from Yahoo webscope – 150K questions.
- The model is tested on a training corpus of 12K queries in English-Hindi mixed scripts (collected manually). The dataset will be made publicly available as soon as the paper is accepted.
- Code is available on Github.
THE IDEA

The idea is analogous to the model discussed in previous post – Simple Markov Model for correcting Transliterated Queries. In first phase that is Spellchecking, we check the query for misspelled words. With the help of combination of words generation heuristics we generate K probable words to each misspelled word. In the candidate query generation all the queries are generated that could be constructed with the substitution words. In this phase, a score is also assigned to each query. In the previous post we used bi-gram Markov model for computation of this score which is replaced by Recurrent Language Model (RLM) that are deep learning language models. Instead of using a simple heuristic for substitution words generation we combine different substitution-word-generation heuristics. In this post, I will use RLM models such as RNN, LSTM and GRU. The deep learning language model that we use is capable of next word prediction which means in a sequence of words we can generate the next term for a given query. Furthermore, with the help of this learning model, it is possible to provide a score corresponding to a query. This score is the error computed by the model. Finally, in the auto-correction phase, each candidate query is provided a score by the RLM and the query having the minimum score is chosen which is contextually plausible than the rest. I am going to omit some details regarding the presented idea as my paper on this topic is currently under review. I will update the post as soon as the paper is available online.
TYPES OF ERRORS CHECKED BY THE MODEL
There are 5 different type of errors that are generally seen (given by Table below), where the non-word substitution is the most probable type of error followed by missing terms and the others.

Apart from the types of errors as shown in above Tables there is a miscellaneous category which consists of queries that have a combination of errors. The model that has been presented here is capable of correcting each type of error.
PROBLEM WITH SUBSTITUTION WORDS GENERATION MODELS
Suppose a user has misspelled the words karna as krn, and psychiatrist as sychatrst. The idea behind Soundex is given in The Soundex Phonetic Algorithm Revisited for SMS Text Representation, Similarity Measure is given in SMS based interface for FAQ retrieval, and LSP is given in Construction of a Semi-Automated model for FAQ Retrieval via Short Message Service. Then the substitution words generated by the words generation heuristics is given in Table below.
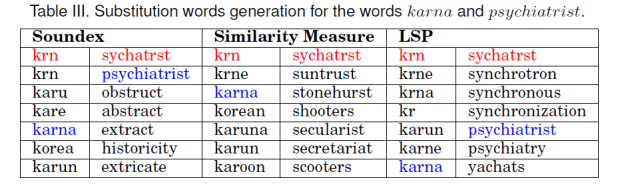
The code for Soundex, Similarity Mearsure and LSP is given in Github. As you can see when used individually, these heuristics are not able to generate the possible substitution early. One good observation is that the correct word is generated most of the time in the first 5 positions by at least one of the heuristics. With a combination of all the three heuristics, it is possible to increase the possibility of occurrence of the correct substitution among the top K words.
>>> from code_run import Kothari as SimilarityMeasure
>>> model = SimilarityMeasure('krn',vocab, K)
>>> model.cal()
['krne', 'karna', 'korean','karuna','karun']
>>> from code_run import Soundex
>>> model = Soundex('krn', K)
>>> model.run()
['krn', 'karu', 'kare', 'karna', 'korea']
>>> from code_run import Aggarwal as LSP
>>> model = LSP('srgry',vocab, K)
>>> model.cal()
['krne', 'kara', 'kr', 'karun', 'karne']
DEEP LEARNING MODEL FOR QUERY CORRECTION
Recurrent Neural Networks (RNN) are generative models that condition the given neural network on every previously seen word and tie the weights at each time step. The DLLM that we use is capable of next word prediction which means in a sequence of words we can generate the next term for a given query. This is shown in figure below

The simplest idea is to tie the output of an RNN together and pass them through a Softmax unit conditioned over entire vocabulary. Thus, the probability of next word in a given sequence can be maximized. Furthermore, with the help of this learning model, it is possible to provide a score corresponding to a query. This score is the error computed by the DLLM, based on which it is possible to select a correct and well-spelled query. In above figure the word vectors are given by
![]()
The weights associated with the input vectors are given by L and the hidden states are shown as![]()
with associated weights as H. H is a weight matrix which interconnects the hidden layers and is responsible for learning long-term relationship among the sequence of words. At each time step-t the hidden states are computed as

where σ is the activation function which can be Sigmoid, Hyperbolic Tangent or ReLU. The output at each time step is given by Equation 10 with Softmax as the activation function. Cost or loss function for the language model is given by

Based on above Equation the score corresponding to a query is computed, according to which it is possible to select a correct and well-spelled query.
During experimentation I observed that the above model is not able to achieve a good performance. After some modifications a better performance for query correction is achieved. I am not going to include these modifications in this post.
WORKING MODEL
The model can be used as
>>> import auto_correct as auto >>> model = auto.auto_correct() >>> model.run() enter a query hw to lrn pythn anddeeplearning eas ily and qkly how to learn python and deep learning easily and quickly 11.2134873867
The output of the model is the corrected query and the score of the query. The parameters to the model are as follows:
- data – The dataset of well spelled queries
- re_train – Set True if training on a new dataset
vocab_size– The size of vocabulary used i.e. the number of unique wordsstep– The size of sliding windowbatch_size– Number of training samples to be passed on one iterationnb_epoch– Total number of iterationembed_dims– Embedding dimension size
For training on a new dataset the queries should be in following format
>>> queries=[]
>>> queries = ["how to handle a 1.5 year old when hitting",
"how can i avoid getting sick in china",
"how do male penguins survive without eating for four months",
"how do i remove candle wax from a polar fleece jacket",
"how do i find an out of print book"]
To train the model use the following command
>>> model =auto.auto_correct(re_train=True,data=queries)
By default the parameters to the model are
>>> model = auto.auto_correct(re_train=True, data=queries,
vocab_size=10000,step=6,batch_size=128,
nb_epoch=5, embed_dims=200)
Since the model is capable of prediction of next word in a sequence so you can predict the next word as
>>> sentence = ['how','to','use','credit'] >>> model.dllm.prediction(model.model, sentence) 'card'
To check the substitution words generated use the following command
>>> model.words_expansion [['how'], ['to'], ['learn'], ['python'], ['and'], ['deep'], ['learning'], ['easily'], ['and'], ['quickly', 'quickl']]
As you can see the number of substitution words are very less as compared to the result of individual heuristics. The presented model uses a combination of multiple heuristics and some search domain reduction methods. In the above results although quickl is not a correctly spelled word but since it is present in the vocabulary thus was used in substitution words generation. Finally to see all the the queries type
>>> model.all_queries [(u'how', u'to', 'learn','python','easily','and','quickly'), (u'how', u'to', 'learn','python','easily','and','quickl')]
CONCLUSION
In this post we have seen how deep learning models such as RNN/LSTM/GRU can be used to correct misspelled queries. The model presented here is not dependent on the type of training data which gives it ability to work efficiently on transliterated queries. A possible drawback of the model is its dependence to the vocabulary words which can be limited by constructing the vocabulary carefully.
