
Automatic question answering is a widely studied problem in natural language processing with applications including entity extraction and information retrieval. Most of the existing works in this area tackles a restricted problem of factoid question answering, while others use answer sentence selection. As of now not much work has been done on text-based question answering, where sufficiently long answers are generated corresponding to each question. In this post I will delineate various deep learning methods and show how these methods can be applied to solve this challenging problem. For experimentation purpose I am going to use Yahoo webscope question answering dataset. In this post I will not include the implementation details related to the project. I am currently working on this project and will update the post as soon as it is complete.
IDEA
The idea is to predict the answer directly from the question instead of extracting the sentences from documents. Thus, the need to generate the answer from existing sentences can be eliminated. For this purpose, we first find the distributed representation of the questions with the help of word vector models. This is followed by query expansion techniques to find similar questions from the dataset. A vector mapping of questions to answers is used to find relevant answer to the given question (in the vector form). Finally, with the help of sequence-to-sequence learning, textual answers are generated from the mapped vectors.
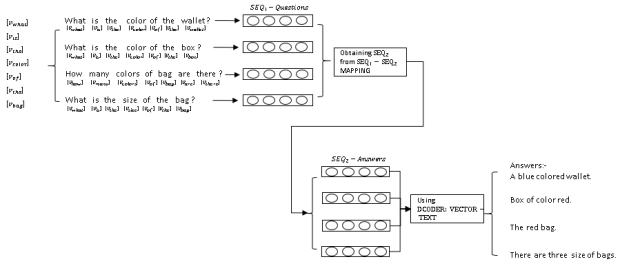
Thus our focus is on following issues:
- How much contextual similarity exists among questions?
- Does a mapping exists between vectors of questions and answers? How efficient are the deep state of art techniques for this mapping?
QUERY EXPANSION
One of the key feature of deep learning models that makes learning feasible is the introduction of distributed word vectors. Deep learning models such as Word2vec (Efficient Estimation of Word Representations in Vector Space) and GloVe (GloVe: Global Vectors for Word Representation) learns word vectors by predicting the surrounding words of the given word in a context window. This way words that are contextually similar are brought together (the vectors are updated using back-propagation). In the question answering system a query can be easily expanded by converting the words in the given query to vectors, and considering those words whose vectors lie in close proximity with the words in given query. This leads to an efficient query expansion.
ANSWER GENERATION
A Recurrent Neural Network conditions the neural network on all previously seen words and tie the weights during every time step. These models are capable of learning the contextual relationship among words in a sentence or among sentences in a paragraph. Given a input sequence as 


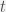

where 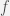
![]()
To train a recurrent neural network(RNN) for predicting the next word of a given sequence, the non-linearity function 
In an ideal model for automatic question answering system the RNN must be modeled to predict the entire sequence of words(answer) given another sequence of words(question). This leads to sequence-to-sequence learning which can be carried out using a encoder-decoder strategy. A RNN is used to encode the input sequences to fixed length vectors. Another RNN is used to map this sequence of vectors to the target sequence. Recurrent neural networks are incapable of storing long term dependencies. The solution to this problem is given in the form of LSTM(Long Short Term Memory) and GRU(Gated Recurrent Unit). In LSTM the introduced gates are the input gate 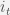



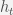

GRU is a simplified version of LSTM with the introduction of a reset gate 
![]()
A question answering model is also described in A Neural Conversational Model.
RESULTS
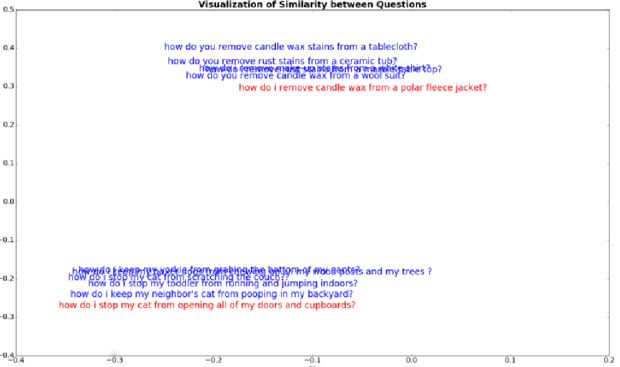
For visulization of results the dimension of each word vector is reduced with the help of PCA. The number of principal components are taken to be 2 so that the final vectors are transformed to 2D. The results of the query expansion task is given in the figure below. The text in red represents the question and the text in blue denotes other questions from dataset.
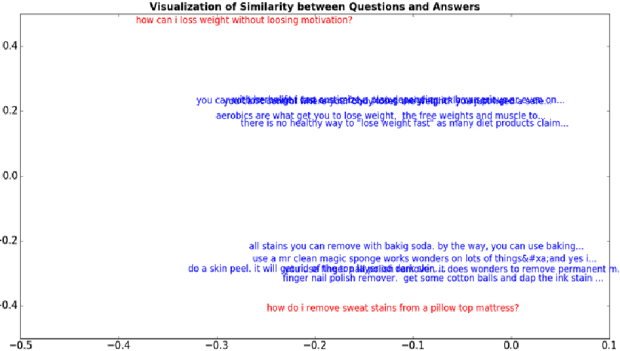
The results for the question answering task is given by the figure below. The text in red represents the question and the text in blue denotes the answers.
WHAT’S NEXT?
In this post I have given a brief discussion about the question answer model. Soon I will update the post with implementation details and source code.
