
The use of mixed languages allows people to express and communicate beyond the constraints of one language. Recently, a common term that has been given to these mixed languages is Hinglish. The use of mixed scripts can be seen in social media such as Watsapp & Facebook, e-commerce like Amazon & Flipkart, and web blogs like this one. Some of the corporate organizations use these scripts to create advertisement taglines such as khushiyon ki home delivery – Dominos, or yeh dil maange more…aha! – Pepsi.


Till now most of us know this usage as Hinglish, yet there is a specific term in linguistics for sentences formed in these mixed scripts, and that is Transliteration, as described in Query Expansion for Multi-script Information Retrieval.
NEED
Here comes the big question – ‘Is there a need to design a system for FAQ retrieval that could handle questions written in mixed scripts?’ Since the use of these mixed queries is rising day by day therefore it is no surprise that answer is yes. The real challenge for this information retrieval system is handling lot of misspellings and ambiguous slang words. One possible reason for the inflated ambiguity is the lack of grammatical rules. In this post I am going to explain the steps to build a simple query corrector that can work for transliterated queries. I will outline the steps explained in the following papers: Language Identification and Disambiguation in Indian Mixed-Script and Construction of a Semi-Automated model for FAQ Retrieval via Short Message Service.
I am assuming that you are familiar with basics of Python. No need to worry about Markov Models, I will explain them later.
THE IDEA

An auto-corrector can be built using three simple steps:
- Check for misspelled words in the given query/sentence/FAQ .
- List of correct words is maintained in files. Separate files for Hindi and English vocabulary, or all words can be kept in a single file.
- For each misspelled word, generate the probable words from the vocabulary with the help of string matching algorithms.
- You can use LCS or Levensthein distance.
- Use a language model to identify the most plausible query among the rest.
- Markov Model: bi-gram or tri-gram.
GENERATE PROBABLE WORDS
Edit distance is a measure of difference in characters between two strings. It uses character based editing operations like deletion, addition and substitution to measure this difference between the two given strings. It generates better probable words than LCS. Mathematically edit distance is represented as,

Where 


Edit distance between two words can be computed as:
>>> import editdistance
>>> editdistance.eval('banana', 'bahama')
2L
For generation of K possible substitution, compare all words in the vocabulary and sort the computed distance. A better approach than the naive edit distance is described in SMS Based Retrieval for SMS Interface. For each token 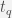
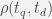
>>> from code_run import Kothari
>>> K = 5
>>> model = Kothari('srgry',vocab, K)
>>> model.cal()
['surgury', 'surgery', 'secretary', 'stronger', 'strawberry']
vocab is the list of words and K is the number of words to be generated.
LANGUAGE MODEL
So far we have generated substitution words for each misspelled word. Now we need to find the correct substitution among the K generated words. Sadly, there is no way to find the actual substitution just from the generated words. So we need to work on some model that can help us to find the actual substitution. A very basic idea is to look for words that are used together more often. The reason for using such a model is the observation that certain words occur in groups more frequently than others. For example, we see the pairs (cosmetic, surgery), (karna, caheye), (credit, card) more frequently than (cosmetic, sugary), (karva, caheye), (credit, cord). Thus if we can compute the occurrence of these groups, then there is a possibility that we can find actual substitutions which will lead to correction of entire query.
A simple Markov Model computes the occurrence of words together i.e. two words : bi – gram, 3 words : tri -gram and so on. The only requirement for such a model is the corpus of well spelled sentences from which the relation among consecutive words can be easily learned. The relation for calculation of probabilities can be represented as:
Where P is the probability of occurrence of two words, x and y, together, f(x, y) represents the frequency of consecutive occurrence of x and y in the training dataset, f(all words) is the count of words in the database and V ie vocabulary is the count of unique words. Thus we can easily compute the probabilities of these bi-gram and tri-grams and store in a hash table with key as the pair of words and probability as value.
To find the most relevant query, the sum of probabilities for each generated combination is computed. This is done by summing up the probabilities of bi_grams table and maximizing the overall probability, i.e.
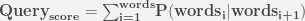
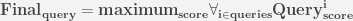
The data should be in following format:
>>> data = [[u'what', u'shape', u'is', u'the', u'bench', u'seat'],
[u'is', u'there', u'a', u'shadow'],
[u'is', u'this', u'one', u'bench', u'or', u'multiple', u'benches']]
Ignore the u’. It is just uni-code encoding. Finally to build up a bi-gram table you need to make a pass through the entire data.
>>> bi_gram = {}
>>> for i in data:
>>> for j in range(0,len(i)-2):
>>> try:
>>> bi_gram[(i[j],i[j+1])]+=1
>>> except:
>>> bi_gram[(i[j],i[j+1])] = 1
Once the bi_gram table is computed, the next step is to generate all the possible queries and to find a contextually plausible query. I have provided a complete code of a bi_gram model on Github. You can use the module as following :
>>> from bigram_model import bigram_auto >>> mod = bigram_auto() >>> mod.model() Enter your query hw ar you how are you
If you want to see the substitution word generation for each misspelled word then use the following command
>>> mod.words_expansion [[u'how', u'hawaii', u'halloween', u'hut', u'huge'], [u'area', u'are', u'air', u'aware', u'attire'], ['you']]
Most of the substitution words are disparate from the actual substitution. The reason for this behavior is the vocabulary which has been generated from the data itself. We can see that the model is highly dependent on the training data. To see all the combination of queries that are formed type the following
>>> mod.queries [(u'halloween', u'are', 'you'), (u'how', u'air', 'you'), (u'hawaii', u'are', 'you'), (u'how', u'area', 'you'), (u'huge', u'aware', 'you'), (u'huge', u'are', 'you'), (u'hawaii', u'aware', 'you'), (u'huge', u'air', 'you'), (u'huge', u'area', 'you'), (u'halloween', u'aware', 'you'), (u'hut', u'are', 'you'), (u'how', u'are', 'you'), (u'huge', u'attire', 'you'), (u'hut', u'attire', 'you'), (u'halloween', u'attire', 'you'), (u'hut', u'air', 'you'), (u'halloween', u'air', 'you'), (u'hut', u'area', 'you'), (u'how', u'aware', 'you'), (u'halloween', u'area', 'you'), (u'hawaii', u'attire', 'you'), (u'hawaii', u'air', 'you'), (u'hut', u'aware', 'you'), (u'how', u'attire', 'you'), (u'hawaii', u'area', 'you')]
The only requirement for training a bi_gram model is the dataset of well-spelled sentences. A reasonable performance can be achieved from this simple model.
DEMERITS
The bi_gram model is not much efficient for robust query correction. Following are some of the demerits of the model:
- Huge bi-gram table construction
- There will be
bi-grams which may be inefficient to train on huge data-sets.
- There will be
- Very basic language model
- The bi-gram model is a very basic model and is incapable to learn relationship among words that are far enough.
- For storing larger context we need 3-grams, 4-grams and so on. This may be highly inefficient and computationally expensive.
- Inefficient substitution word generation heuristics.
- The edit distance heuristic for word generation is not able to detect some of the possible error types such as phonetic errors.
WHAT’S NEXT?
In the next post I will show how to improve the auto-correction model by working on all of the above disadvantages of the bi-gram model. We will explore how deep learning models can be used in place of Markov model and how to combine various heuristics to have better performance.

Awesome man!… I can easily go through the blog and understood it very nicely…. Keep up the good work…. Excited to see the next post….
LikeLike